第5章: 合成によるコーディング
関数合成術
これがcomposeです:
const compose = (...fns) => (...args) => fns.reduceRight((res, fn) => [fn.call(null, ...res)], args)[0];...怖がらないで!これはcomposeのレベル9000超サイヤ人形態です。理解を進めるため、引数の可変長実装は横に置き、2つの関数を合成するシンプルな形式を考えましょう。これを理解すれば、抽象化をさらに進め、任意の数の関数で動作すると考えられます(証明も可能です!)。親愛なる読者の皆様に、より親しみやすいcomposeを紹介します:
const compose2 = (f, g) => x => f(g(x));fとgは関数、xはそれらを通過する"パイプ"される値です
合成は関数の品種改良のようなもの。特性を組み合わせたい関数を選び、混ぜ合わせて全く新しい関数を生み出すのです。使用例は次の通り:
const toUpperCase = x => x.toUpperCase();
const exclaim = x => `${x}!`;
const shout = compose(exclaim, toUpperCase);
shout('send in the clowns'); // "SEND IN THE CLOWNS!"2つの関数の合成は新しい関数を返します。これは理にかなっています:ある型(ここでは関数)の単位を2つ合成すると、その型の新たな単位を得られるはずです。レゴブロックを2つ繋げてもLincoln Log(林肯積木)は得られません。ここには理論があり、いずれ明らかになる基本法則が存在します
私たちのcompose定義では、gがfより先に実行され、データが右から左へ流れる構造になります。これはネストした関数呼び出しよりも遥かに読みやすい構造です。composeがない場合、上記は次のように記述されます:
const shout = x => exclaim(toUpperCase(x));内側から外側ではなく、右から左に実行されます。順序が重要な例を見てみましょう:
const head = x => x[0];
const reverse = reduce((acc, x) => [x, ...acc], []);
const last = compose(head, reverse);
last(['jumpkick', 'roundhouse', 'uppercut']); // 'uppercut'reverseはリストを反転し、headは最初の要素を取得します。これにより非効率ながら効果的なlast関数が得られます。合成における関数の順序が重要であることが分かります。左から右へ実行するバージョンを定義することも可能ですが、現状の方が数学的な定義により近い形式です。その通り、合成は数学書から直接取り入れた概念なのです。実際、あらゆる合成に当てはまる特性を見る時が来たようです
// associativity
compose(f, compose(g, h)) === compose(compose(f, g), h);合成は結合的(associative)であり、グループ化の方法が結果に影響しません。文字列を大文字化する場合、次のように書けます:
compose(toUpperCase, compose(head, reverse));
// or
compose(compose(toUpperCase, head), reverse);composeの呼び出しをどのようにグループ化しても結果が同じであるため、可変引数のcomposeを書いて次のように使用できます:
// previously we'd have to write two composes, but since it's associative,
// we can give compose as many fn's as we like and let it decide how to group them.
const arg = ['jumpkick', 'roundhouse', 'uppercut'];
const lastUpper = compose(toUpperCase, head, reverse);
const loudLastUpper = compose(exclaim, toUpperCase, head, reverse);
lastUpper(arg); // 'UPPERCUT'
loudLastUpper(arg); // 'UPPERCUT!'結合的性質により、結果が同等であるという柔軟性と安心感が得られます。やや複雑な可変引数定義は、本書のサポートライブラリに含まれており、lodash、underscore、ramdaなどのライブラリで見られる標準的な定義です
結合性の利点として、関数のグループを独自の合成として抽出・束ねられる点が挙げられます。前回の例をリファクタリングしてみましょう:
const loudLastUpper = compose(exclaim, toUpperCase, head, reverse);
// -- or ---------------------------------------------------------------
const last = compose(head, reverse);
const loudLastUpper = compose(exclaim, toUpperCase, last);
// -- or ---------------------------------------------------------------
const last = compose(head, reverse);
const angry = compose(exclaim, toUpperCase);
const loudLastUpper = compose(angry, last);
// more variations...正解も不正解もありません。私たちはレゴブロックを自由に組み合わせているだけです。通常はlastやangryのように再利用可能な形でグループ化するのが最善です。ファウラーの「リファクタリング」をご存知なら、「関数の抽出」プロセスと認識できるでしょう。オブジェクトの状態を気にする必要がない点が異なります
ポイントフリースタイル
ポイントフリースタイルとは、データを明示的に言及する必要のないスタイルです。第一級関数、カリー化、合成が連携してこのスタイルを実現します
ヒント:
replaceとtoLowerCaseのポイントフリーバージョンは付録C - ポイントフリー用ユーティリティで定義されています。是非参照してください!
// not pointfree because we mention the data: word
const snakeCase = word => word.toLowerCase().replace(/\s+/ig, '_');
// pointfree
const snakeCase = compose(replace(/\s+/ig, '_'), toLowerCase);replaceを部分適用しているのが分かりますか?1引数関数をデータがパイプを通るようにしています。カリー化により、各関数がデータを受け取り処理して渡す準備が整います。ポイントフリーバージョンでは関数構築にデータを必要としない点も注目すべき点で、ポイントフル版ではwordが必須となります
別の例を見てみましょう
// not pointfree because we mention the data: name
const initials = name => name.split(' ').map(compose(toUpperCase, head)).join('. ');
// pointfree
// NOTE: we use 'intercalate' from the appendix instead of 'join' introduced in Chapter 09!
const initials = compose(intercalate('. '), map(compose(toUpperCase, head)), split(' '));
initials('hunter stockton thompson'); // 'H. S. T'ポイントフリーコードは不要な名前を排除し、簡潔で汎用的なコードを保つのに役立ちます。関数型コードの良いリトマス試験紙と言えるでしょう。例えばwhileループは合成できません。ただし、ポイントフリーは諸刃の剣で、時々意図を曖昧にすることがあります。全ての関数型コードがポイントフリーである必要はありません。可能な場合は目指し、それ以外は通常の関数を使えば良いのです
デバッグ
一般的な間違いは、2引数関数であるmapを部分適用せずに合成しようとすることです
// wrong - we end up giving angry an array and we partially applied map with who knows what.
const latin = compose(map, angry, reverse);
latin(['frog', 'eyes']); // error
// right - each function expects 1 argument.
const latin = compose(map(angry), reverse);
latin(['frog', 'eyes']); // ['EYES!', 'FROG!'])合成のデバッグに苦戦している場合は、この便利だが不純なtrace関数を使って状況を確認できます
const trace = curry((tag, x) => {
console.log(tag, x);
return x;
});
const dasherize = compose(
intercalate('-'),
toLower,
split(' '),
replace(/\s{2,}/ig, ' '),
);
dasherize('The world is a vampire');
// TypeError: Cannot read property 'apply' of undefinedここで何か問題が発生しています。traceで確認しましょう
const dasherize = compose(
intercalate('-'),
toLower,
trace('after split'),
split(' '),
replace(/\s{2,}/ig, ' '),
);
dasherize('The world is a vampire');
// after split [ 'The', 'world', 'is', 'a', 'vampire' ]ああ!配列を処理するため、toLowerをmapする必要がありました
const dasherize = compose(
intercalate('-'),
map(toLower),
split(' '),
replace(/\s{2,}/ig, ' '),
);
dasherize('The world is a vampire'); // 'the-world-is-a-vampire'trace関数はデバッグ目的で特定時点のデータを確認できます。HaskellやPureScriptなどの言語も開発を容易にする同様の関数を備えています
合成はプログラム構築の道具となり、幸運なことに堅牢な理論に支えられています。この理論を検証しましょう
圏論
圏論は集合論、型理論、群論、論理など複数分野の概念を形式化できる数学の抽象的分野です。オブジェクト、射、変換を扱い、プログラミングと密接に対応します。以下は各理論から見た同等概念の比較表です
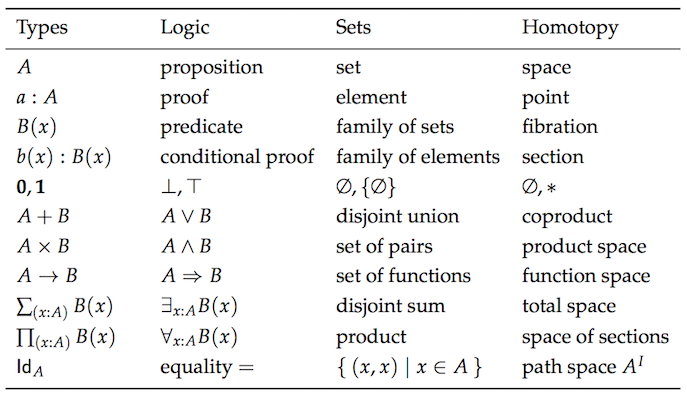
怖がらせるつもりはありませんでした。これら全ての概念に精通している必要はありません。重複がいかに多いか理解し、圏論がこれらの統合を目指す理由を把握してほしいのです
圏論には...圏と呼ばれる概念があります。次の構成要素を持つ集合体として定義されます:
- オブジェクトの集合
- 射の集合
- 射の合成という概念
- 恒等射と呼ばれる特別な射
圏論は様々な事象をモデル化できますが、現在関心のある型と関数に適用してみましょう
オブジェクトの集合 オブジェクトはデータ型です。例: String、Boolean、Number、Objectなど。データ型を取り得る全ての値の集合と見なします。Booleanを[true, false]の集合、Numberを全ての数値の集合と考えることができます。型を集合として扱うと集合論を活用可能です
射の集合 射は日常使う純粋関数です
射の合成という概念 ご想像の通り、これが最新のツールcomposeです。合成が結合的であることは圏論の要件であり、偶然の一致ではありません
合成を説明する図表:
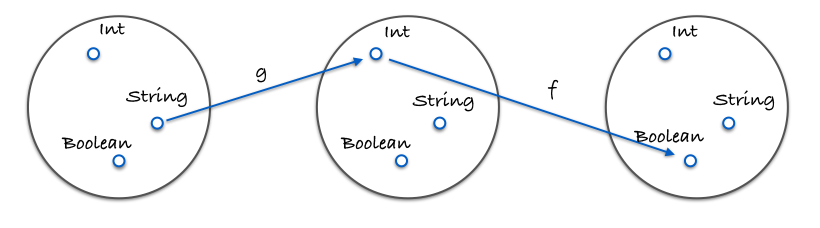
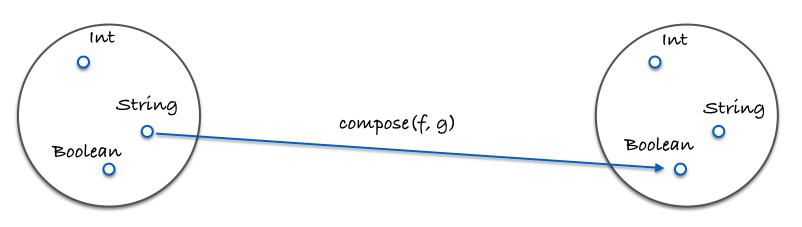
コードによる具体例:
const g = x => x.length;
const f = x => x === 4;
const isFourLetterWord = compose(f, g);恒等射と呼ばれる特別な射idという有用な関数を紹介します。入力を受け取りそのまま返す単純な関数です:
const id = x => x;「これが一体何の役に立つんだ?」と思うかもしれません。次章で多用しますが、今はデータの代役を務める関数と考えてください。日常のデータに偽装した関数です
idは合成と調和する必要があります。単項関数fに対して常に成り立つ特性です:
// identity
compose(id, f) === compose(f, id) === f;
// true数値の恒等特性と同じですね!すぐに理解できなければ、時間をかけて無意味さを噛みしめてください。やがてidが至る所で使われるのを見ることになります。ポイントフリーコード作成時に特に有用です
これが型と関数の圏です。初めての方はまだ圏の意義が曖昧かと思いますが、本書を通じて理解を深めます。現時点では少なくとも合成に関する知恵(結合性と恒等性)を与えてくれると理解してください
他の圏の例?ノードをオブジェクト、エッジを射とする有向グラフの圏や、数値をオブジェクト、>=を射とする圏(実際には任意の半順序または全順序が圏になります)などがあります。数多くの圏が存在しますが、本書では上記の定義に限定します。表面をなぞったので次に進みましょう
まとめ
合成はパイプのように関数を接続します。データはアプリケーションを流れるように設計され、純粋関数は入力から出力への変換なので、この連鎖を断ち切るとソフトウェアは無意味になります
合成を最上位の設計原則と位置付けます。アプリをシンプルかつ合理的に保つためです。圏論はアプリ設計、副作用のモデル化、正確性の保証で重要な役割を果たします
実践的なアプリケーション例を見る段階に来ました。サンプルアプリを作成しましょう
練習問題
以下の各練習問題では、次の構造のCarオブジェクトを扱います:
{
name: 'Aston Martin One-77',
horsepower: 750,
dollar_value: 1850000,
in_stock: true,
}練習開始!
compose()を使用して以下の関数を書き換えてください
const isLastInStock = (cars) => {
const lastCar = last(cars);
return prop('in_stock', lastCar);
};
以下の関数を考慮してください:
const average = xs => reduce(add, 0, xs) / xs.length;練習開始!
ヘルパー関数averageを使用し、averageDollarValueを合成形式でリファクタリングしてください
const averageDollarValue = (cars) => {
const dollarValues = map(c => c.dollar_value, cars);
return average(dollarValues);
};
練習開始!
compose()と他のポイントフリースタイル関数を使用してfastestCarをリファクタリングしてください。ヒント:append関数が役立つかもしれません
const fastestCar = (cars) => {
const sorted = sortBy(car => car.horsepower, cars);
const fastest = last(sorted);
return concat(fastest.name, ' is the fastest');
};